One of the first things you need to check and optimize when working on your technical SEO is the robots.txt file. A problem or misconfiguration in your robots.txt can cause critical SEO issues that negatively impact your rankings and traffic.
In this post, you will learn what a robots.txt file is, why you need it, and how to optimize it for SEO.
What Is A Robots.txt File?
A robots.txt is a text file that resides in the root directory of your website and gives search engine crawlers instructions as to which pages they can crawl and index during the crawling and indexing process.
In a typical scenario, your robots.txt file should have the following contents:
User-agent: *
Allow: /
Sitemap: https://example.com/sitemap.xml
This allows all bots to access your website without any blocking. It also specifies the sitemap location to make it easier for search engines to locate it.
If you have read my previous article on how search engines work, you know that during the crawling and indexing stage, search engines try to find pages available on the public web that they can include in their index.
When visiting a website, the first thing they do is to look for and check the contents of the robots.txt file. Depending on the rules specified in the file, they create a list of the URLs they can crawl and later index for the particular website.

The contents of robots.txt are publicly available on the Internet. Unless protected otherwise, anyone can view your robots.txt file, so this is not the place to add content you don’t want others to see.
Why Is a Robots.txt File Important?
Having a robots.txt is important for several reasons, even if you don’t want to exclude any pages or directories of your website from appearing in search engine results. The most common use cases of robots.txt are the following:
1. To block search engines from accessing specific pages or directories of your website - For example, look at the robots.txt below and notice the disallow rules. These statements instruct search engine crawlers not to index the specific directories. Notice that you can use an * as a wild card character.
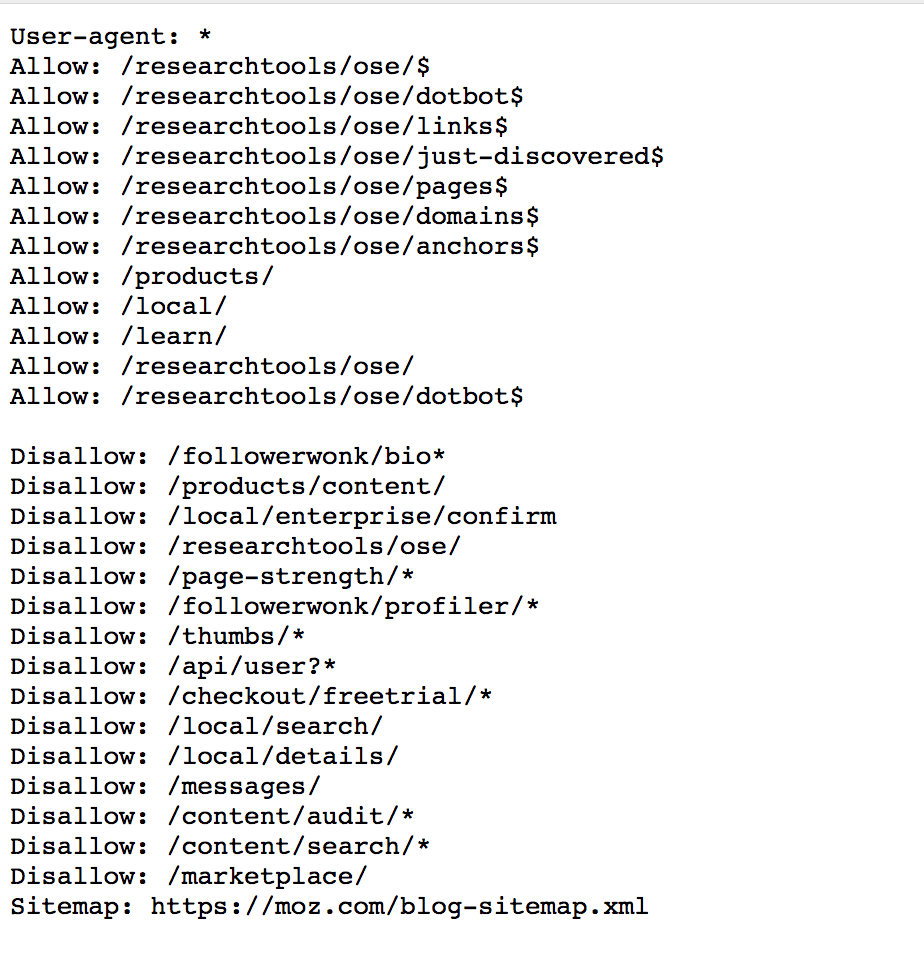
2. Control crawling - Crawling and indexing can be very resource-intensive with a big website. Crawlers from various search engines will try to crawl and index your whole site, which can create serious performance problems.
In this case, you can use the robots.txt to restrict access to certain parts of your website that are unimportant for SEO or rankings. This way, you reduce the load on your server and make the whole indexing process faster.
How Does Robots.txt File Work?
The robots.txt file has a very simple syntax. There are some predefined keyword/value combinations you can use.
The most common are User-agent, Disallow, Allow, Crawl-delay, and Sitemap.
User-agent: Specifies which crawlers should take into account the directives. You can use an * to reference all crawlers or specify the name of a crawler. See examples below.
You can view all available names and values for the user-agent directive here.
User-agent: * - includes all crawlers.
User-agent: Googlebot - instructions are for Google bot only.
Disallow: The directive instructs a user-agent (specified above) not to crawl a URL or part of a website.
The value of disallow can be a specific file, URL, or directory. Look at the example below taken from Google support.

Allow: The directive explicitly tells which pages or subfolders can be accessed. This is applicable for the Googlebot only.
You can use the allow to access a specific sub-folder on your website, even though the parent directory is disallowed.
For example, you can disallow access to your Photos directory but allow access to your BMW sub-folder under Photos.
User-agent: *
Disallow: /photos
Allow: /photos/bmw/
Crawl-delay: You can specify a crawl-delay value to force search engine crawlers to wait for a specific amount of time before crawling the next page from your website. The value you enter is in milliseconds.
It should be noted that the crawl-delay is not considered by Googlebot. In the majority of cases, you shouldn’t make use of the crawl-delay directive.
Sitemap: The sitemap directive is supported by the major search engines, including Google, and it is used to specify the location of your XML Sitemap.
Even if you don’t specify the location of the XML sitemap in the robots, search engines can still find it.
For example, you can use this:
Sitemap: https://example.com/sitemap.xml
Important: Robots.txt is case-sensitive. This means that if you add this directive, Disallow: /File.html will not block file.html.
How To Create A Robots.txt?
Creating a robots.txt file is easy. All you need is a text editor (like brackets or notepad) and access to your website’s files (via FTP or control panel).
Before getting into the process of creating a robots.txt file, the first thing to do is to check if you already have one.
The easiest way to do this is to open a new browser window and navigate to https://www.yourdomain.com/robots.txt
If you see something similar to the one below, you already have a robots.txt file, and you can edit the existing file instead of creating a new one.
User-agent: *
Allow: /
How to edit your robots.txt
Use your favorite FTP client and connect to your website’s root directory.
Robots.txt is always in the root folder (www or public_html, depending on your server).
Download the file to your PC and open it with a text editor.
Make the necessary changes and upload the file back to your server.
How to create a new robots.txt
If you don’t already have a robots.txt, then create a new .txt file using a text editor, add your directives, save it, and upload it to the root directory of your website.
Important: Make sure that your file name is robots.txt and not anything else. Also, have in mind that the file name is case-sensitive so it should be all lowercase.
Where do you put robots.txt?
robots.txt should always reside in the root of your website and not in any folder.
How To Test And Validate Your Robots.txt?
There are three ways to test your robots.txt file.
- You can use a free robots.txt validator. It will tell you if there are any blocking or issues with the syntax.
- You can view the Robots.txt report in Google Search Console, located under Settings.
- You can use the URL Inspection tool of Google Search Console to test individual pages.
Robots.txt SEO Best Practices
When it comes to SEO, consider the following best practices:
- Test your robots.txt and ensure you are not blocking any parts of your website that you want to appear in search engines.
- Do not block CSS or JS folders. During the crawling and indexing process, Google can view a website like a real user, and if your pages need the JS and CSS to function properly, they should not be blocked.
- If you are on WordPress, blocking access to your wp-admin and wp-includes folders is unnecessary. WordPress does a great job using the meta robots tag.
- Don’t try to specify different rules per search engine bot. It can get confusing and challenging to keep up-to-date. Better use user-agent:* and provide one set of rules for all bots.
- If you want to exclude pages from being indexed by search engines, you better do it using the "noindex" tag in the header of each page and not through the robots.txt.
What happens if you don’t have a robots.txt file?
If a robots.txt file is missing, search engine crawlers assume that all publicly available pages of the particular website can be crawled and added to their index.
What happens if the robots.txt is not well-formatted? It depends on the issue. If search engines cannot understand the file's contents because it is misconfigured, they will still access the website and ignore whatever is in robots.txt.
What happens if I accidentally block search engines from accessing my website? That’s a big problem. For starters, they will not crawl and index pages from your website, and gradually, they will remove any pages already available in their index.
Two Important things to know about robots.txt
- First, any rules you add to the robots.txt are directives only. This means it’s up to search engines to obey and follow the rules. In most cases, they do, but If you have content you don’t want to be included in their index, the best way is to password-protect the particular directory or page.
- The second thing is that even if you block a page or directory in robots, it can still appear in the search results if it has links from other pages already indexed. In other words, adding a page to robots.txt does not guarantee that it will be removed or not appear on the web.
Robots.txt and WordPress
Everything you have read about robots.txt applies to WordPress websites as well. WordPress, by default, is using a virtual robots.txt file. This means you cannot directly edit the file or find it in the root of your directory.
The only way to view the file's contents is to type https://www.yourdomain.com/robots.txt in your browser.
The default values of WordPress robots.txt are:
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
When you enable the “Discourage search engines from indexing this site” option under Search Engine Visibility Settings, the robots.txt becomes:
User-agent: *
Disallow: /
Which blocks all crawlers from accessing the website.
How do I edit robots.txt in WordPress?
Since you cannot directly edit the virtual robots.txt file provided by WordPress, the only way to edit it is to create a new one and add it to the root directory of your website.
When a physical file is present in the root directory, the virtual WordPress file is not taken into account.
Conclusion
You don’t have to spend too much time configuring or testing your robots.txt. What is important is to have one and to check through Google Search Console that you are not blocking search engine crawlers from accessing your website.
You must do it once when creating your website or as part of your technical SEO audit.


