The NoIndex tag is very useful for keeping your SEO in good shape. In this guide, you'll learn when and how to use it correctly.
What Is a Noindex Tag?
A "noindex tag" is a special HTML directive instructing search engines not to index a particular page. When search engine crawlers encounter this tag on the page's HTML, they remove the page from their index and, thus, from the search results.
You can use the noindex tag to control which pages of your website you want to be included in the index, as it works page-by-page.
Why It's Important For SEO?
The Noindex tag is important for SEO because it allows you to control which pages of your site you want to be included in search engines' index without removing them from your website.
For example, pages used as special landing pages for paid ads, pages shown to users when they complete an action (thank you pages), or tag pages.
Here is a practical use case to understand how the noindex tag can help you with SEO.
With the recent deployment of Google's Helpful Content Update, many websites' rankings were demoted because of 'unhelpful content'. One way to get your website out of the algorithmic penalty is to remove pages that are considered unhelpful from the Google index.

Instead of removing the pages from your website and showing users a 404 page (Not Found), you can add the noindex tag so that users can visit the pages. However, Google will not consider this for ranking purposes.
Best Practices For Implementing Noindex Tag
As with everything in SEO, misuse of an element can potentially generate the opposite results. To avoid such issues, follow these best practices when using the noindex tag:
1. Don't block the page in robots.txt - this is the biggest mistake many webmasters make and should be avoided.
For Google to process the noindex tag, the page must not be blocked from crawling in robots.txt. As you'll see below, blocking a page in robots.txt is not the same as adding the noindex tag.
If you want to keep a page out of the index, add the noindex tag in the header (using one of the methods described below) and make the page available for crawling. Google will read the page, process the noindex tag, and deindex it.
2. Use it Strategically - Apply the Noindex tag to pages that don't provide value to search engines. This includes admin, thank you, and other non-essential pages.
Only Noindex pages when absolutely necessary. Overusing the tag can lead to important content being missed by search engines, impacting your site's overall visibility.
3. Monitor Your GSC Reports - Regularly check which pages are Indexed and Noindexed. You can view the "Page Indexing" report in Google Search Console, particularly the "Excluded by 'noindex tag' "section.
If there are pages you want in the index, remove the noindex tag and use the URL Inspection tool to "Request Indexing" to get them back to the index.
4. Remove NoIndex Pages From Sitemaps: Remove Noindexed pages from your sitemap to avoid confusing search engines. Your sitemap should only include pages you want indexed.
If you use WordPress and Yoast SEO, a page is set to noindex, it is automatically excluded from the sitemap.
How To Add Noindex Tag To a Page?
Let's review the three ways you can use to add a noindex tag to a page:
1. HTML Meta Tag
The most commonly used method is adding this code to the <head> of an HTML page, which instructs search engines not to index the particular page.
<meta name="robots" content="noindex">
The noindex tag can be combined with other values. Here are some examples:
<meta name="robots" content="noindex, follow"> – don't index the page, but follow any links to discover more pages.
<meta name="robots" content="index, nofollow"> – don’t index the page, and don’t follow any links.
<meta name="googlebot" content="noindex"> - prevent only Googlebot from not indexing the page.
Remember that the robots meta tag can have other values besides the noindex. Read this for a complete list.
The default value for all pages in many CMS is:
<meta name="robots" content="index, follow"> – which means indexing the page and following any links.
2. Using the X-Robots-Tag HTTP header
When you cannot edit the page's HTML directly or want to add the noindex to many pages programmatically, you can use the X-Robots-Tag HTTP Header.
Other use cases include:
Non-HTML Files: When you need to control the indexing of non-HTML files like PDFs, images, and videos. Unlike the meta tags within HTML files, the X-Robots-Tag can be applied directly via HTTP headers.
Dynamic Content: For dynamically generated pages where adding a meta tag isn't feasible. The header can be set programmatically based on specific conditions.
Comprehensive Noindexing: When you want to apply Noindex to an entire directory or multiple file types without editing each file individually. This can be more efficient and less error-prone.
For example, you can exclude PDF files from being indexed by adding the following code to your .htaccess file.
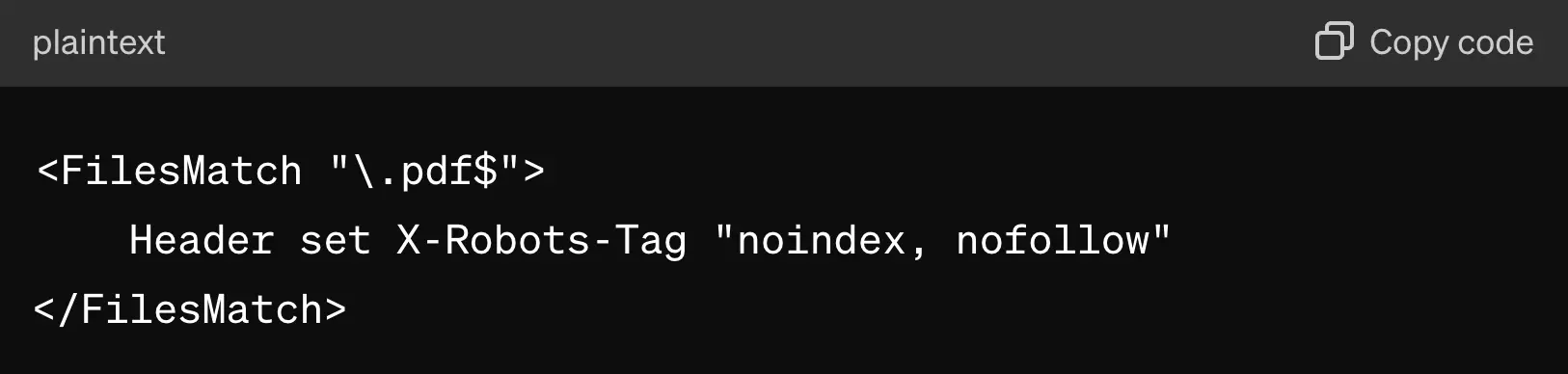
Implementing the X-Robots-Tag is a technical task; if you don't have the necessary programming knowledge, assigning it to an experienced web developer is best.
3. WordPress
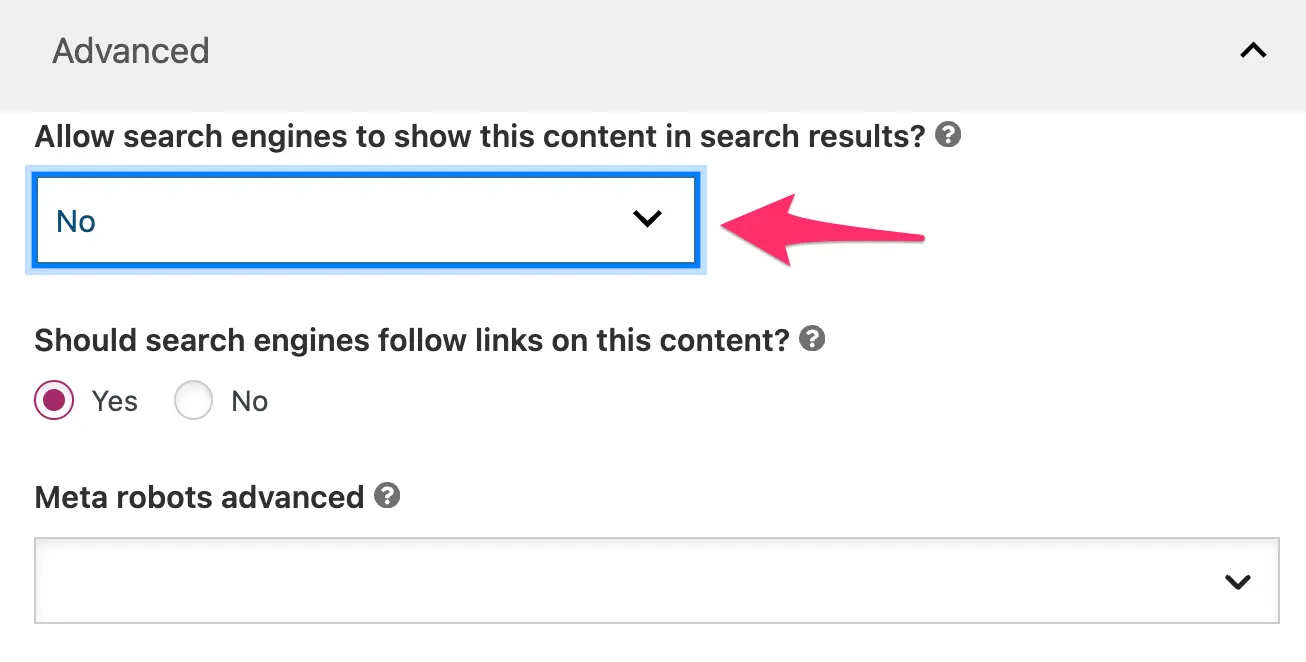
For WordPress users, adding the noindex meta tag is very easy with Yoast SEO. By setting "Allow search engines to show this content in search results?" to NO, the meta tag is added to the header and the page is excluded from the sitemap.
Differences Between Robots File and Robots Meta Tag?
Many people confuse the role of a robots.txt file and the robots meta tag. They serve different purposes in controlling how search engines interact with your website.
Here's a simple explanation of the differences:
You can use the robots.txt file to instruct search engines which parts of your website they can crawl (or not). These instructions are placed in a file called "robots.txt" in your website's root folder.
For example, this code tells all search engines (User-agent: *) not to crawl the /admin/ and /private/ directories.
User-agent: *
Disallow: /admin/
Disallow: /private/
Instructions in a robots.txt file may prevent crawling, but they do not necessarily prevent indexing of URLs if they have links pointing to them.
When to Use Each
- Use Robots.txt: To block search engines from crawling certain directories or files across your site.
- Use Robots Meta Tag: When you need to control the indexing of individual pages.
Conclusion
To improve your SEO, you must ensure that only helpful pages are included in the Google index. Pages that don't add any value should be removed from the index using the noindex tag.
Use the Noindex tag strategically when you need to exclude pages from search engines without removing them from your site, keeping your content accessible to visitors but not to crawlers.



