- 1. Server Errors (5xx)
- 2. Page with Redirect
- 3. Alternate Page with Proper Canonical Tag
- 4. Excluded by 'noindex' Tag
- 5. Not Found (404)
- 6. Soft 404
- 7. Blocked Due to Other 4xx Issue
- 8. Crawled - Currently Not Indexed
- 9. Duplicate, Google Chose Different Canonical Than User
- 10. Blocked by robots.txt
- 11. Unauthorized Request Errors (401)
- 12. Discovered - Currently Not Indexed
- 13. Duplicate Without User-Selected Canonical
- 14. Blocked Due to Access Forbidden (403)
- 15. Indexed, Though Blocked by robots.txt
- Conclusion
In this post, you will learn how to use the Google Search Console to identify and fix common errors.
If you don't have a Google Search Console account, the first step is to add and verify your website. Next, you can login to Google Search Console and click 'Pages' under 'Indexing' to view the 'Page Indexing' report.
Scroll to the part 'Why Pages Aren't Indexed' to see the different errors.
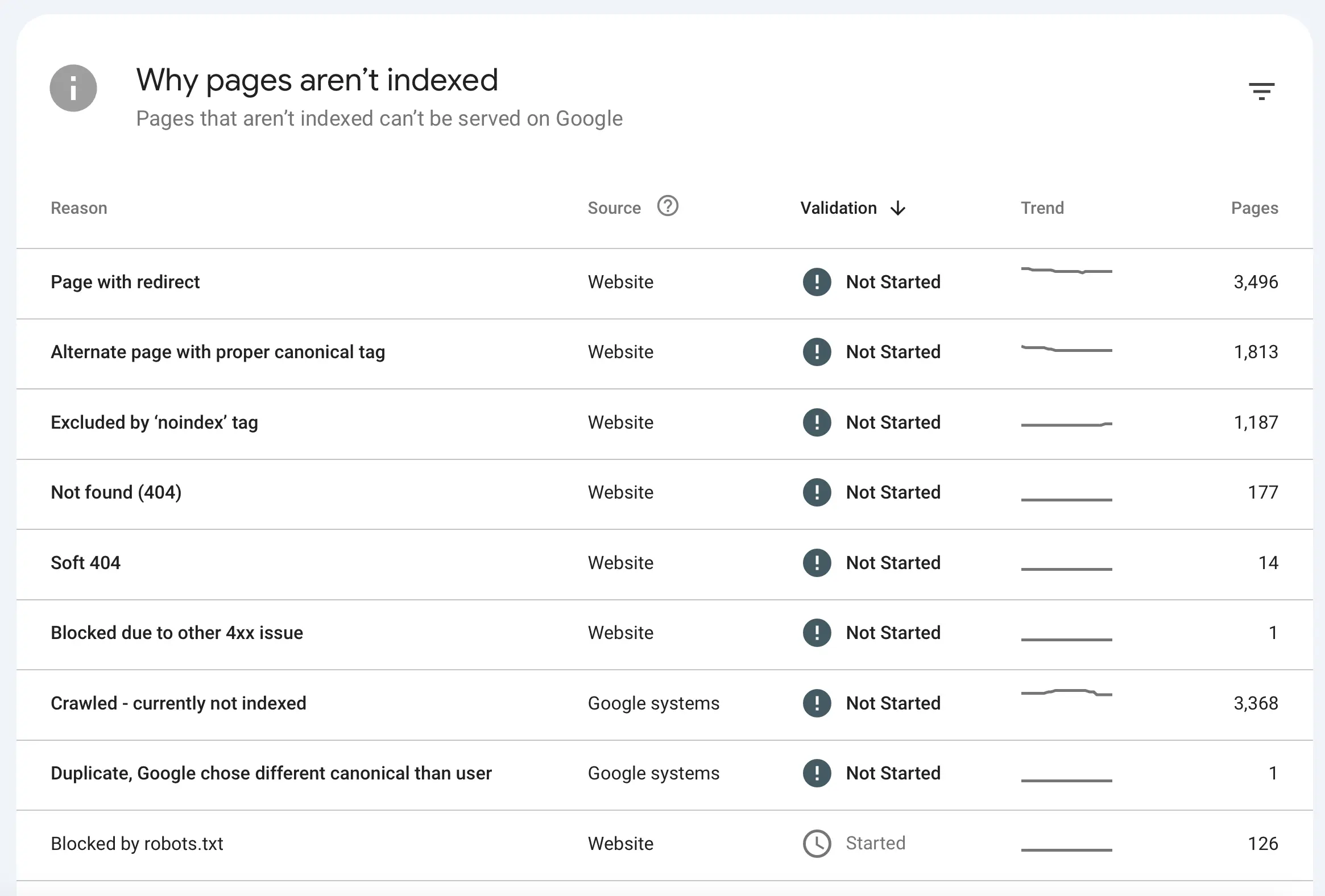
1. Server Errors (5xx)
A 5xx error (e.g., 500, 502, 503) indicates a problem with your server that prevents Googlebot from accessing your page. It could be a server crash, overload, or misconfiguration.
Normally, you should not have any Server Errors. If you have a lot of errors, then this means that your server has issues, and you should investigate more to find out why.
If you have a few errors, then the page could most probably not be accessed temporarily. This means that you can request that Google re-index the page.
How to fix it:

- Click on one of the affected pages to get a menu with options on the right.
- Click Inspect URL.
- Click "Test Live URL" to see if it’s still an issue.
- If everything is okay, click the "Request Indexing" button.
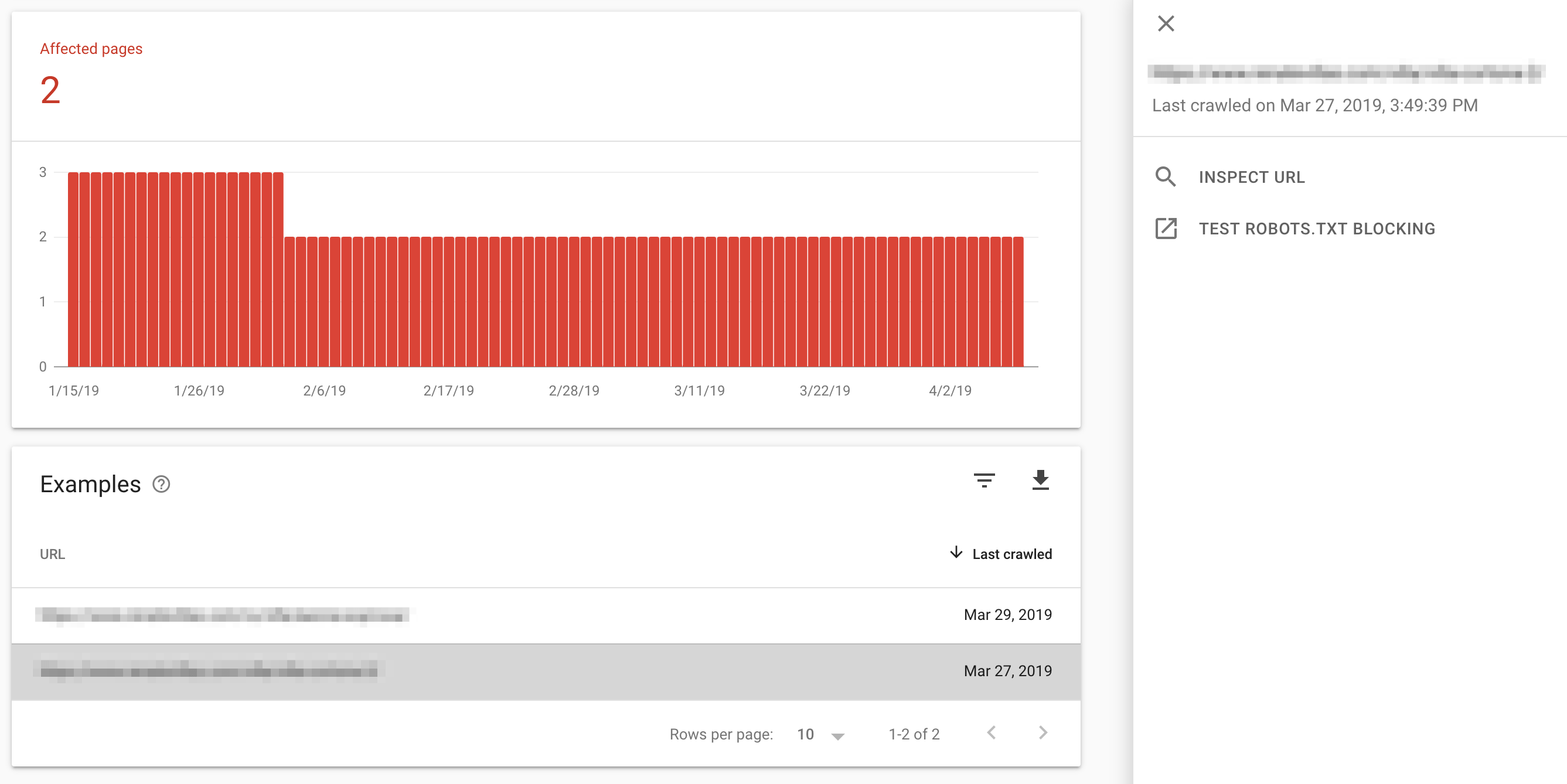
If the problem persists and you continue to see server errors, you’ll need to investigate your server setup and how Googlebot is crawling your site.
Start by checking the Crawl Stats Report in Google Search Console under Settings > Crawl Stats. This report provides information on how often Googlebot visits your site and whether there are any errors.
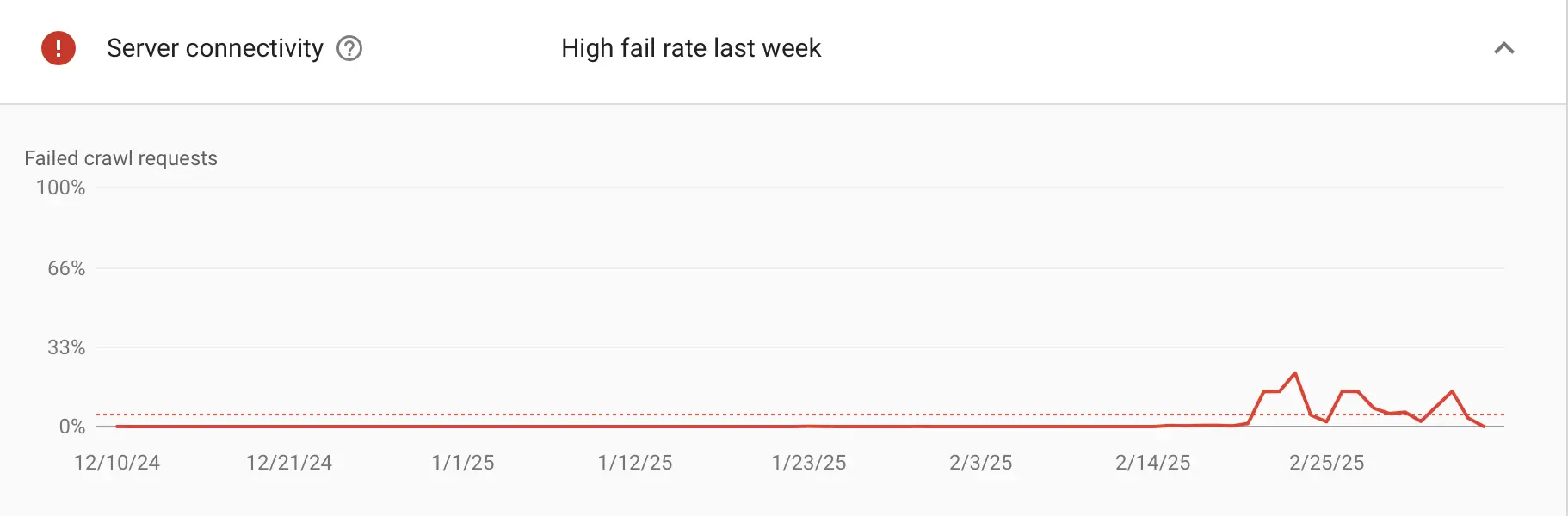
If you see any Host had problems last week messages, this means your server had issues which led to 5XX errors. Monitor this closely and if the errors don't go away, examine your server logs.
Look specifically for 5xx errors in the logs, such as “500 Internal Server Error” or “503 Service Unavailable.” Pay close attention to the timestamps. If these errors occur during peak traffic hours, it could be a sign that your server cannot handle high demand and may need upgrading (usually it's a RAM issue).
Additionally, if certain pages consistently trigger errors, it may indicate an issue with their configuration, such as incorrect file permissions or a problematic script causing failures.
When you're done investigating, use Validate Fix in the Page indexing report to ask Google to verify if the issue is resolved.
2. Page with Redirect
When you get a ‘page with redirect error,’ it means that Googlebot found a page that redirects to another URL (e.g., 301 or 302 redirect). This isn’t always an error unless the redirect is unintentional or leads to a dead end.
It’s normal to see many pages listed here. This happens because Google considers URL variations, such as URLs with and without a trailing slash (/) and with www or non-www, as separate pages.
For example, example.com/page and example.com/page/ might be treated as separate URLs leading to one version listed as a 'page with redirect'.
How to fix it:
- Click on the INSPECT URL
- Get more details about the errors
- Click the TEST LIVE URL
The first thing to do is check if the redirect is intentional. If that's the case, no fix is needed, ensure it points to a relevant, live page. Use the URL Inspection tool on the final URL. It should show as “Indexed” or give reasons if not.
If the redirect leads to a 404 or 5xx error, update it to point to the correct destination.
If the redirected URL is in your XML sitemap, replace it with the target URL. Also update any internal links that still use the old URL, so users and Google always go directly to the new URL.
Make the necessary changes and click the Validate Fix button.
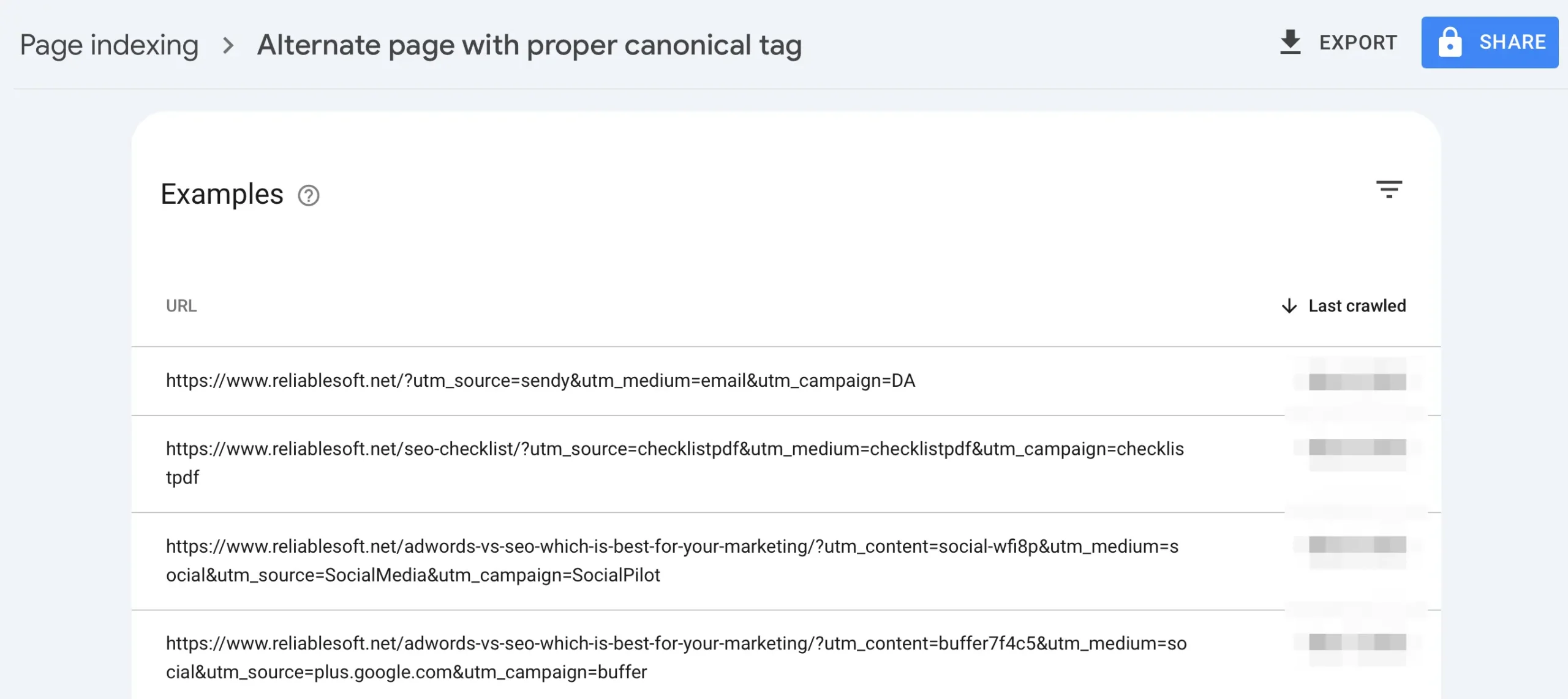
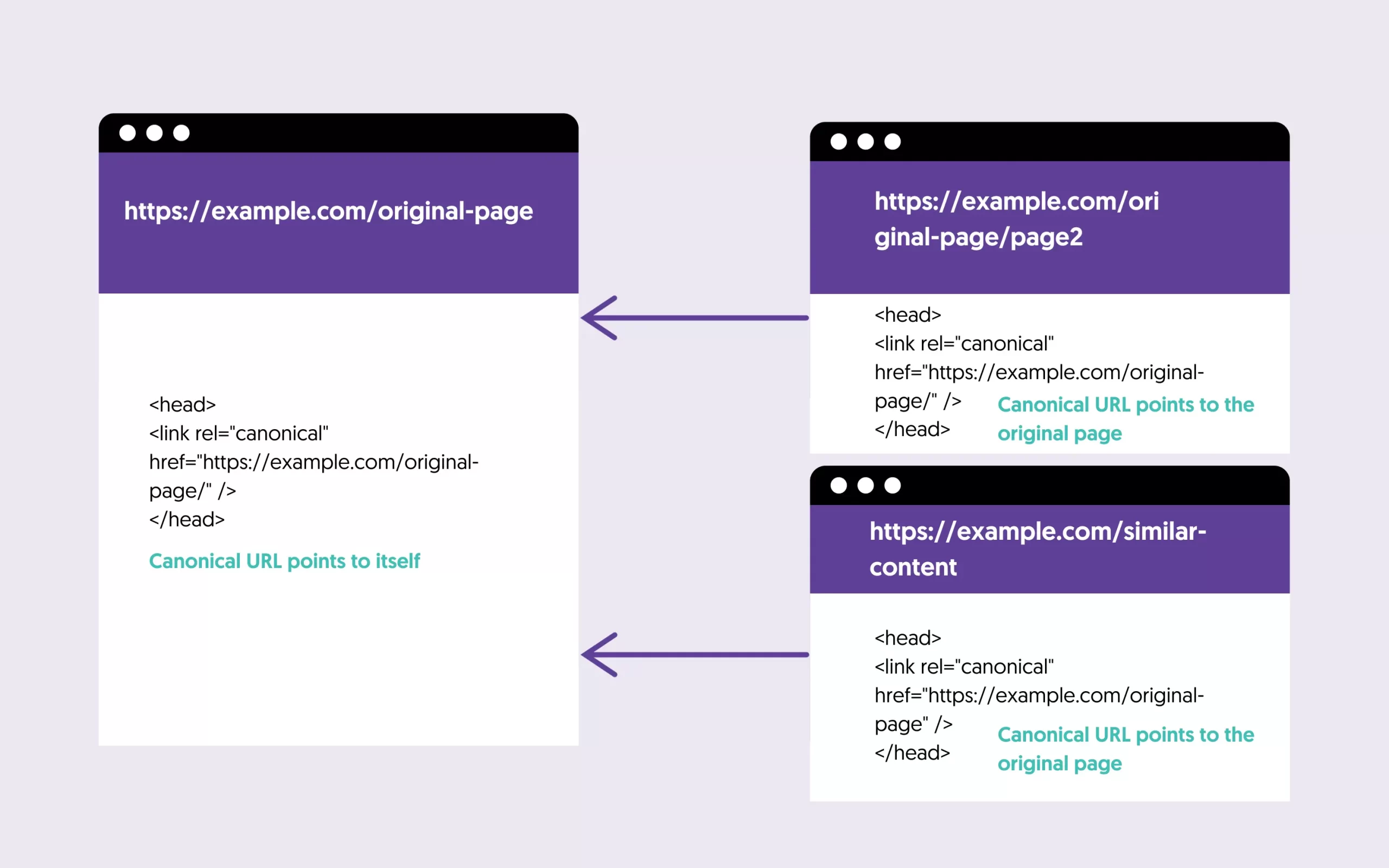
3. Alternate Page with Proper Canonical Tag
Google found a page that’s a duplicate of another but has a canonical tag pointing to the preferred version. It’s not indexed because Google respects the canonical.
For example, if you have pages with utm parameters, they will be listed here.
How to fix it:
If the page is meant to be a duplicate (e.g., a product variant, a UTM-tagged URL, or a session-based URL), then the canonical tag is working correctly, and no action is needed.
To be safe, you can use the URL Inspection tool to verify that the canonical tag points to the correct version of the page. Also, ensure that the preferred page is indexable and not blocked by robots.txt or a noindex tag.
If the canonical tag points to the wrong page, update the HTML of the affected page to point to the correct URL.
4. Excluded by 'noindex' Tag
This is not actually an error. This means a page was submitted for indexing (through your sitemap) but has the ‘noindex’ directive instructing search engines not to add it to their index.
You should review the list of pages with the 'no index' tag and ensure you don’t want them in the Google index.
If a page was wrongly tagged as ‘noindex,’ remove the page directive from the header and ask Google to re-crawl it.
5. Not Found (404)
These kinds of errors are easy to fix. This means that Googlebot tried to crawl a URL that doesn’t exist on your server, returning a 404 error.
In most cases, this can be a false alarm. So, the first thing to do is to check that the page is correctly not found.
Click on a page from the list and then the INSPECT URL button.
While waiting to get the data from Google Index, open a new browser window and type the URL.
If the page is found on your website and you want to add it to the Google Index then:
- Click the TEST LIVE URL button.
- Click the REQUEST INDEXING.
- Go Back to the report and click VALIDATE FIX.
If this is a page that indeed returns a 404 code and you don’t want Google to index it, you have two options:
First, leave it as it is. Google will gradually remove the page from the index. This is normal and expected to happen for pages that are no longer valid or deleted for a valid reason.
Second, to redirect the page using a 301 redirection to a related page on your website.
6. Soft 404
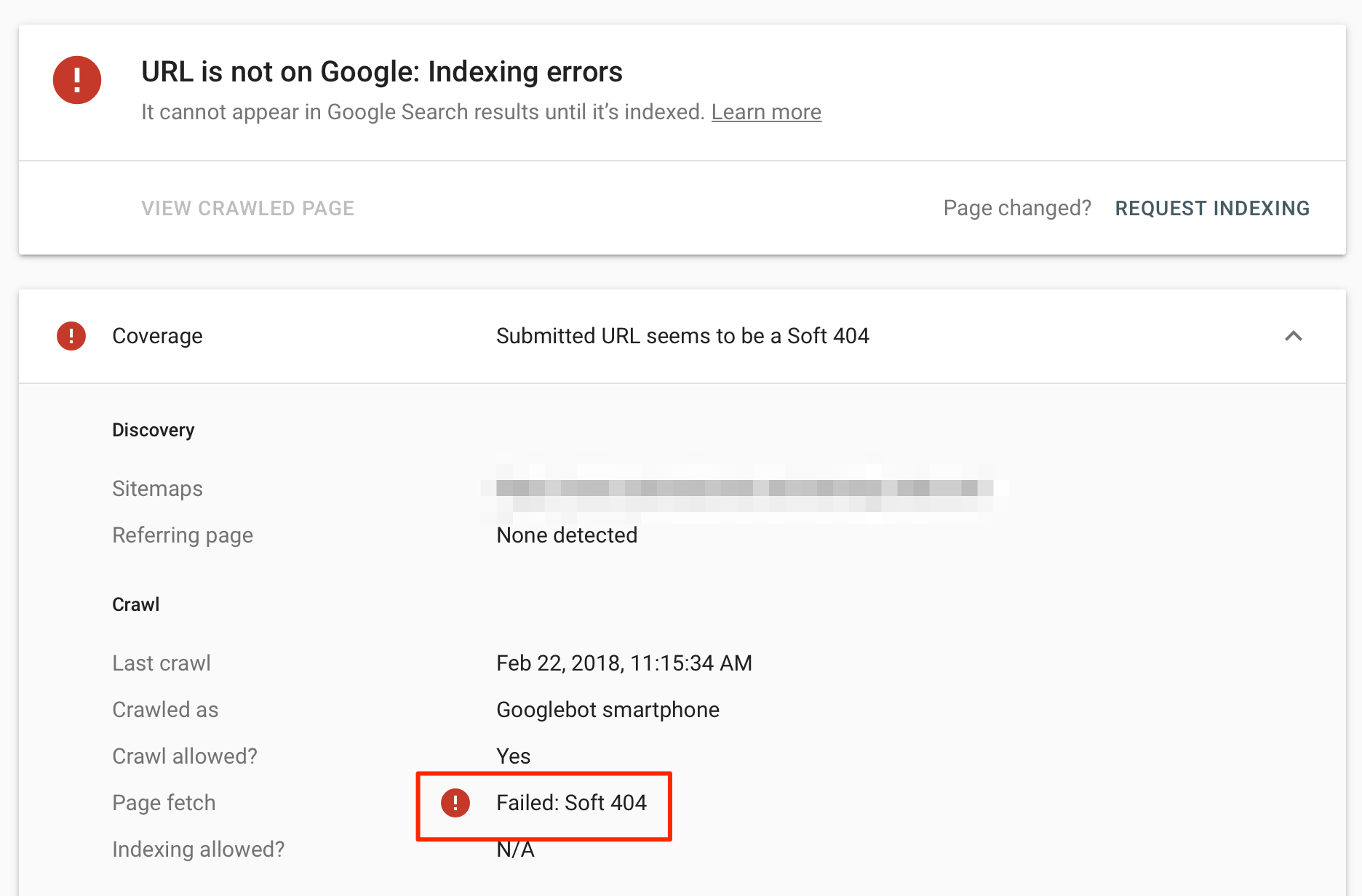
When you get a soft 404 error, it means that the page was not found (because it does not exist), but instead of telling search engines that it should be ignored, it returned a valid code (200 OK).
You may have pages on your website that cannot be accessed directly but only after a user completes a specific action.
For example, let’s say your checkout page is only shown to users after they add an item to their shopping cart.
If you still have the page listed in your sitemap, Google will try to crawl it but it will not find it because no items were added to the cart.
What to do for soft 404 errors?
- You will need to either return a 404 code for pages that are not valid
- Remove them from your sitemap so that Google will not access them
- Redirect them to a valid page
- Do nothing. Sometimes soft 404 errors are normal and expected.
7. Blocked Due to Other 4xx Issue
Googlebot encountered a 4xx error (excluding 404/401/403), like 410 (Gone) or 429 (Too Many Requests), preventing access. Rather than listing each separately, GSC groups them under “Blocked due to other 4xx issue.”
The result is that Google did not index that URL because it couldn’t crawl it successfully.
How to fix it:
First, use Google Search Console’s URL Inspection tool to find the exact error code. This will help you understand why Googlebot couldn’t access the page.
Next, determine if the error was intentional or a mistake. Some 4xx errors, like 410 (Gone), are expected if you remove a page intentionally. But if the error is unexpected, you’ll need to investigate further.
Look for patterns in the affected URLs. If all the blocked URLs share a common parameter, for example (?ref=facebook), this could point to an issue with how your site handles those URLs.
Check your server logs to see why Googlebot’s requests are failing. Sometimes, a firewall setting or security rule might be blocking Google. In other cases, a required parameter might be missing from the URL. Adjusting these settings can resolve the issue.
Once you’ve fixed the problem, click ‘Validate Fix’ in Google Search Console. This tells Google to recheck the affected pages. If the issue is resolved, Google will mark it as fixed.
8. Crawled - Currently Not Indexed
Googlebot crawled the page but chose not to index it, possibly due to low quality, thin content, or crawl budget prioritization.
If you notice .webp images listed in this report, don’t worry, this is normal. Google sometimes crawls image URLs separately, but since images aren’t standalone web pages, they won’t be indexed like regular content. You can safely ignore them.
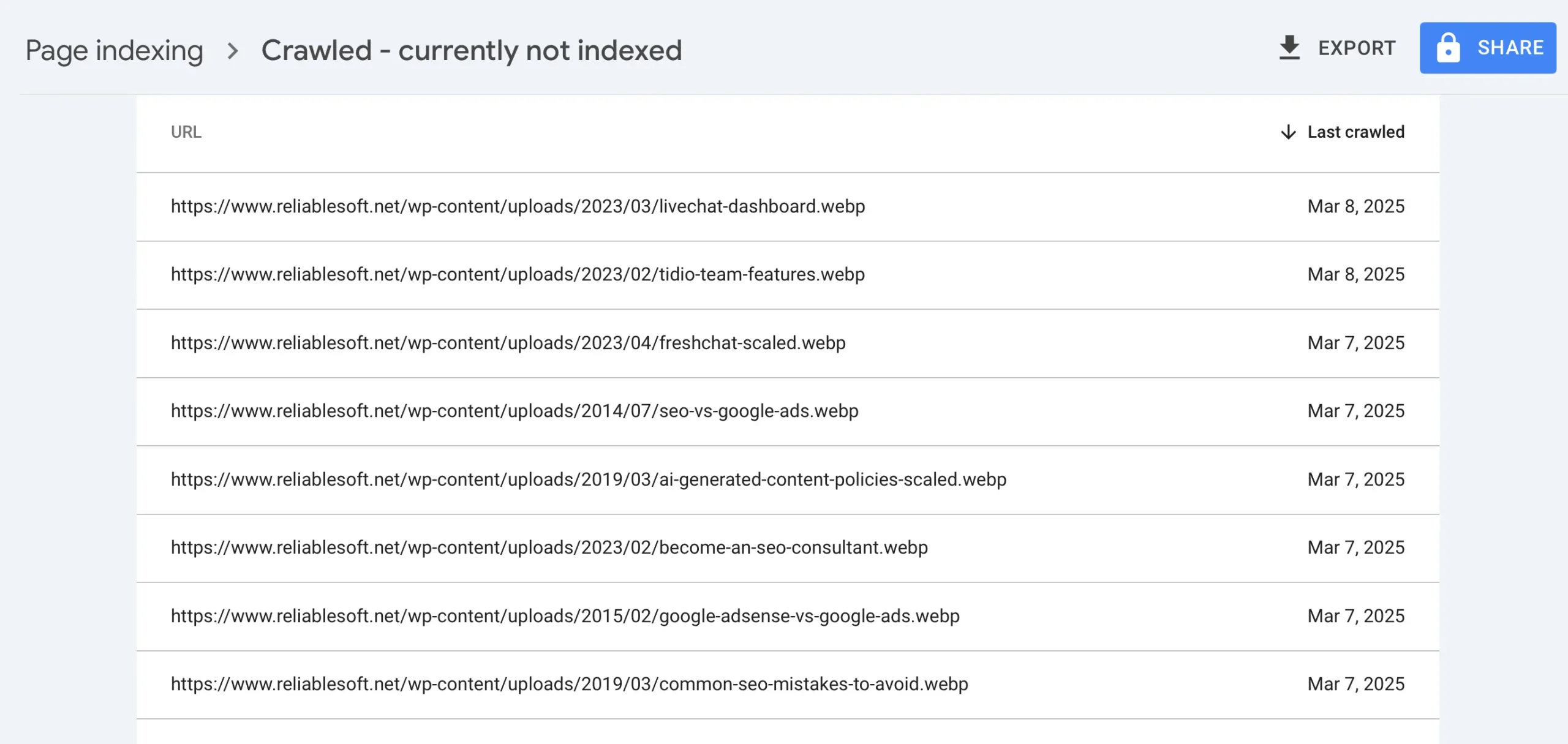
However, if actual web pages are listed, you should investigate further. The first step is to check the content quality. Pages with very little useful information, duplicate content, or poorly structured text are less likely to be indexed.
Expanding the content, improving readability, and adding valuable information can help.
It’s also important to check for technical issues. Use Google Search Console’s URL Inspection tool to see how Google views the page. If the page has noindex tags, canonical issues, or load errors, these must be fixed to allow indexing.
If everything seems fine, but the page is still not indexed, consider internally linking to it from other important pages on your site. Google is more likely to index pages that are well-connected within your website structure.
After making improvements, you can request indexing in Google Search Console.
9. Duplicate, Google Chose Different Canonical Than User
This happens when you tell Google which version of a page to index using a canonical tag, but Google decides to ignore it and pick a different page instead.
For example, let’s say you have two similar product pages:
- example.com/shoes-blue/ (your preferred page, set as canonical)
- example.com/blue-shoes/ (another version that Google thinks is better)
If the second page has more backlinks, a better internal linking structure, or receives more traffic, Google may decide to index it instead of your chosen URL.
To fix this, first check whether Google’s choice makes sense. If it does, update your site to use that version instead.
If you still want your preferred page indexed, you must improve it by adding internal links and backlinks and making sure the content is more valuable than the competing page.
You can also link from your preferred page to the Google chosen page.
After making these changes, you can request indexing in Google Search Console. Google may take some time to make its decision, so you need to monitor this regularly.
10. Blocked by robots.txt
Your robots.txt file is blocking Googlebot from crawling the pages, and they are not indexed or served on Google.
In your site’s robots.txt file, there is a disallow rule that applies to the URL, so when Googlebot tried to crawl it, it stopped.
In the example below, the thank-you.html page is blocked from crawling.
User-agent: *
Disallow: /thank-you.html
If you want pages indexed, remove the relevant rules from the robots.txt file and resubmit the page to Google using the URL inspection tool. Google will eventually crawl and index the page.
If you want the page removed from the index, consider removing the robots.txt blocking and adding a "noindex" tag to it.
11. Unauthorized Request Errors (401)
A page is included in your sitemap but Google cannot access it because it is password protected.
Since these pages are not publicly available, you should:
- Remove them from your sitemap
- Add a ‘noindex’ directive in the page’s header
- Block the directory (or protected areas) in your robots.txt file
12. Discovered - Currently Not Indexed
Google has found the page through your sitemap or links but hasn’t crawled or indexed it yet, often due to crawl budget or low priority.
You can use the URL Inspection tool and "Request Indexing" to see if the content gets indexed.
If not, you should review the content to ensure it's unique and aligns with the user's search intent.
Check that the page is included in your XML sitemap and add links from other website pages and external sources.
13. Duplicate Without User-Selected Canonical
This issue occurs when multiple pages on your site have similar or identical content, but you haven’t told Google which one is your preferred version through a canonical tag.
As a result, Google decides on its own which page to index.
To fix this problem, add a canonical tag to each duplicate page, pointing to the version you want Google to index. This helps Google understand which page is the primary one and prevents it from indexing multiple versions unnecessarily.
For example, let’s say you have two pages with very similar content:
- example.com/red-running-shoes/ (your preferred page)
- example.com/running-shoes-red/ (a duplicate version)
You need to add a canonical tag to the duplicate page to tell Google that the first URL is the main version. In the HTML <head> section of example.com/running-shoes-red/, insert:
<link rel="canonical" href="https://example.com/red-running-shoes/">
14. Blocked Due to Access Forbidden (403)
Googlebot got a 403 error, meaning it was forbidden from accessing the page. This is often due to server permissions, such as IP restrictions, .htaccess rules, or server firewall settings.
First check that the error is still valid and make the necessary adjustments to your server to allow Googlebot to access the page.
Confirm the changes with the URL Inspection tool and request indexing.
15. Indexed, Though Blocked by robots.txt
A page has been submitted for indexing (through your sitemap) or found by links, but there is a rule in your robots.txt file instructing search engines not to index it.
If you don't want a page indexed by Google, the correct way to do this is:
- Allow the page to be crawled in robots.txt
- Add a 'noindex' tag to the page.
Blocking the page through robots.txt is not enough to keep a page out of Google's index.
Conclusion
Don’t panic when you see errors in your Google Search Console account. In many cases, errors are valid and expected.
Your priority is to solve any CRAWLED - CURRENTLY NOT INDEXED and NOT FOUND (404) errors since these errors are directly related to your rankings.



